Pipelines¶
Overview¶
A pipeline comprises one or more nodes that are (in many cases) connected with each other to define execution dependencies. A node is an instance of a configurable component that commonly only implements a single unit of work to make it reusable. A unit of work can represent any task, such as loading data, pre-processing data, analyzing data, training a machine learning model, deploying a model for serving, querying a service, or sending an email.

Note though that multiple components might implement the “same” task. For example, one component might load data from a SQL database, whereas another component might download data from S3 storage. Conceptually both components load data, but how they load it is entirely different.
Elyra supports two types of components: generic components and custom components. A pipeline that utilizes only generic components is called a generic pipeline, whereas a pipeline that utilizes generic components and/or custom components is referred to as runtime-specific pipeline.
Pipelines are assembled using the Visual Pipeline Editor. The editor includes a palette, the canvas, and a properties panel, shown on the left, in the center, and the right, respectively.
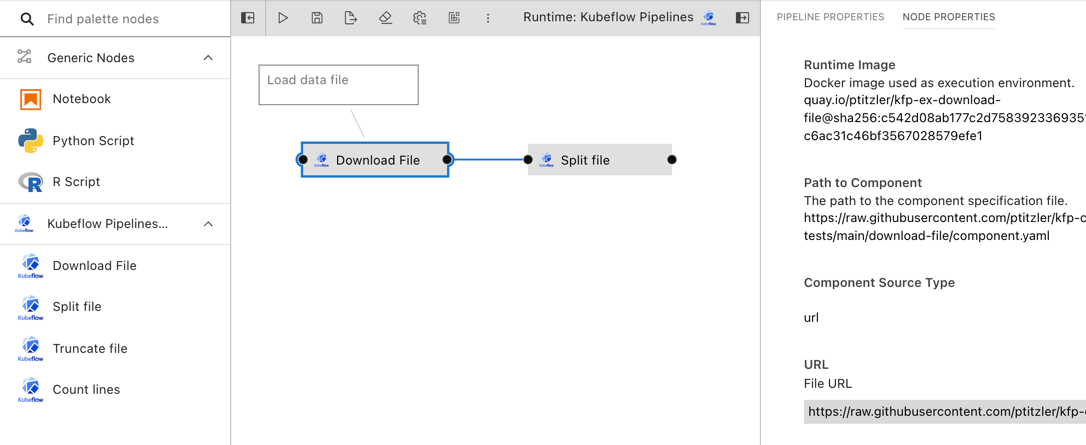
Please review the Best practices for file-based pipeline nodes topic in the User Guide if your pipelines include generic components.
Elyra pipelines support three runtime platforms:
- Local/JupyterLab
- Kubeflow Pipelines (with Argo or Tekton workflow engines)
- Apache Airflow
Generic pipelines¶
A generic pipeline comprises only of nodes that are implemented using generic components. This Elyra release includes three generic components that allow for execution of Jupyter notebooks, Python scripts, and R scripts.
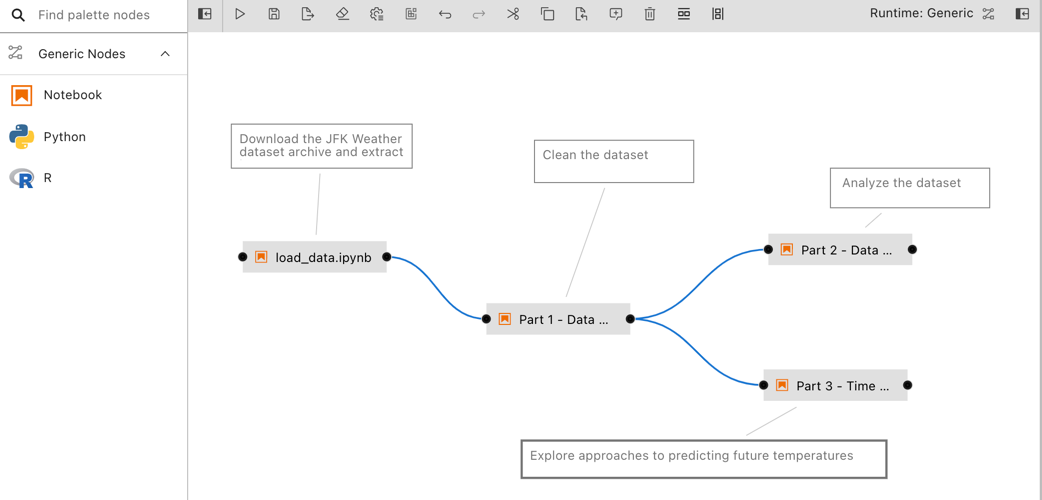
Generic pipelines are portable, meaning they can run locally in JupyterLab, or remotely on Kubeflow Pipelines or Apache Airflow.
Runtime-specific pipelines¶
A runtime-specific pipeline is permanently associated with a runtime platform, such as Kubeflow Pipelines or Apache Airflow. A runtime-specific pipeline may include nodes that are implemented using generic components or custom components for that runtime.
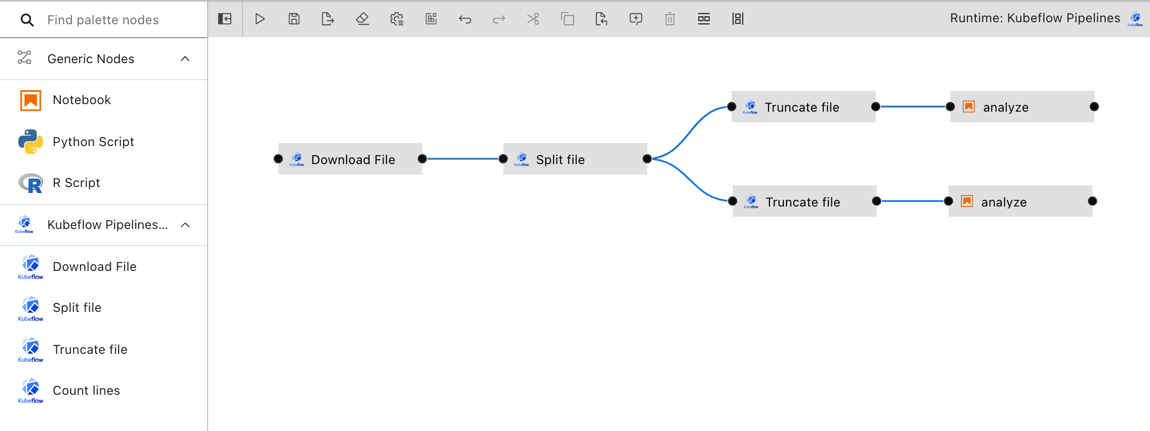
For illustrative purposes the Elyra component registry includes a couple example custom components. You can add your own components as outlined in Managing custom components.
Note that it is not possible to convert a generic pipeline to a runtime-specific pipeline or a runtime-specific pipeline from one type to another.
Creating pipelines using the Visual Pipeline Editor¶
The tutorials provide comprehensive step-by-step instructions for creating and running pipelines. To create a pipeline using the editor:
Open the JupyterLab Launcher and select the desired pipeline editor type (Generic, Kubeflow Pipelines, or Apache Airflow).

Defining pipeline properties¶
Expand the properties panel and select the ‘pipeline properties’ tab.
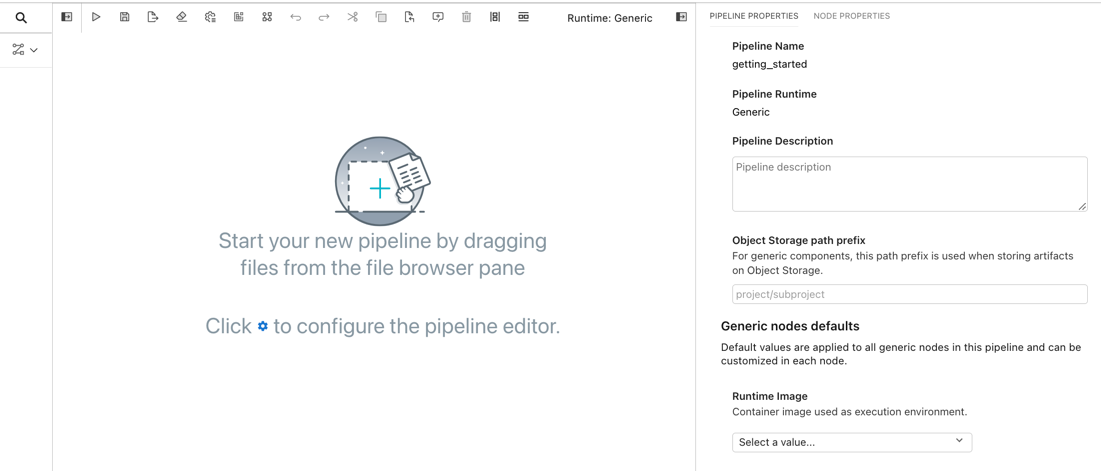
Pipeline properties include:
An optional description, summarizing the pipeline purpose.
Properties that apply to every generic pipeline node. In this release the following properties are supported:
Object storage path prefix. Elyra stores pipeline input and output artifacts in a cloud object storage bucket. By default these artifacts are located in the
/<pipeline-instance-name>path. The example below depicts the artifact location for several pipelines in thepipeline-examplesbucket: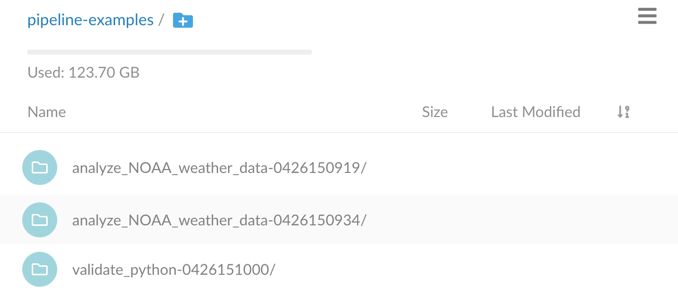
Configure an object storage path prefix to store artifacts in a pipeline-specific location
/<path-prefix>/<pipeline-instance-name>: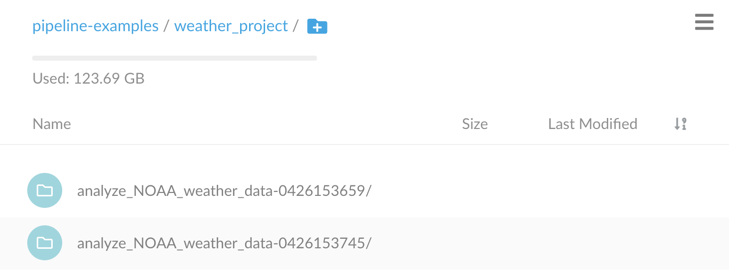
Default values that apply to every pipeline node that is implemented by a generic component. These values can be overridden for each node.
- Runtime image
- Identifies the container image used to execute the Jupyter notebook or script. Select an image from the list or add a new one that meets your requirements.
- The value is ignored when the pipeline is executed locally.
- Environment variables
- A list of environment variables to be set in the container that executes the Jupyter notebook or script. Format:
ENV_VAR_NAME=value. Entries that are empty (ENV_VAR_NAME=) or malformed are ignored.
- A list of environment variables to be set in the container that executes the Jupyter notebook or script. Format:
- Data volumes
- A list of Persistent Volume Claims (PVC) to be mounted into the container that executes the Jupyter notebook or script. Format:
/mnt/path=existing-pvc-name. Entries that are empty (/mnt/path=) or malformed are ignored. Entries with a PVC name considered to be an invalid Kubernetes resource name will raise a validation error after pipeline submission or export. - The referenced PVCs must exist in the Kubernetes namespace where the generic pipeline nodes are executed.
- Data volumes are not mounted when the pipeline is executed locally.
- A list of Persistent Volume Claims (PVC) to be mounted into the container that executes the Jupyter notebook or script. Format:
- Kubernetes secrets
- A list of Kubernetes Secrets to be accessed as environment variables during Jupyter notebook or script execution. Format:
ENV_VAR=secret-name:secret-key. Entries that are empty (ENV_VAR=) or malformed are ignored. Entries with a secret name considered to be an invalid Kubernetes resource name or with an invalid secret key will raise a validation error after pipeline submission or export. - The referenced secrets must exist in the Kubernetes namespace where the generic pipeline nodes are executed.
- Secrets are ignored when the pipeline is executed locally. For remote execution, if an environment variable was assigned both a static value (via the ‘Environment Variables’ property) and a Kubernetes secret value, the secret’s value is used.
- A list of Kubernetes Secrets to be accessed as environment variables during Jupyter notebook or script execution. Format:
- Runtime image
Adding nodes¶
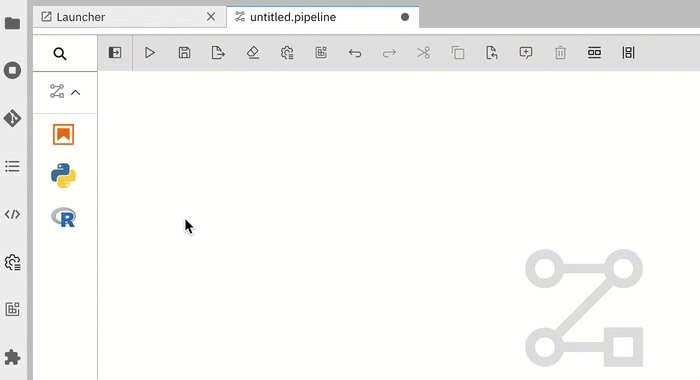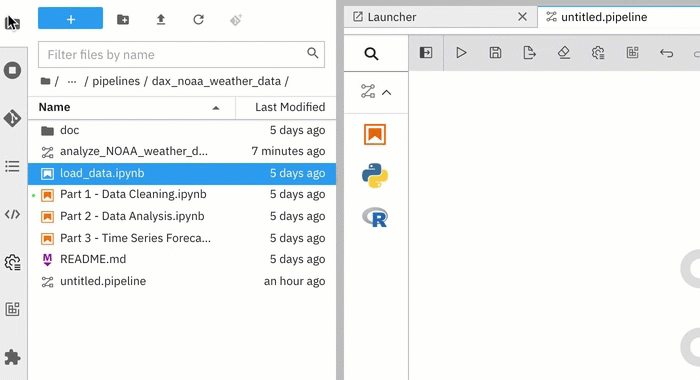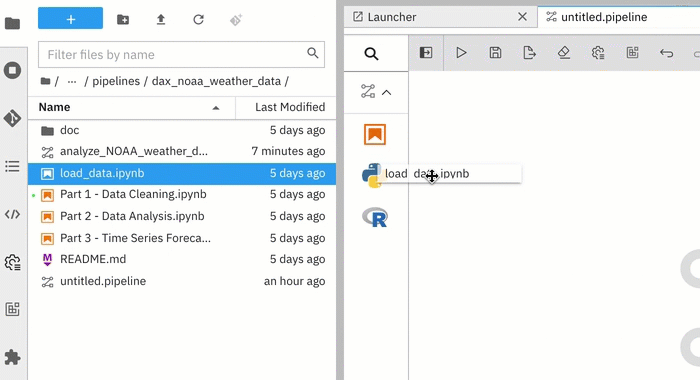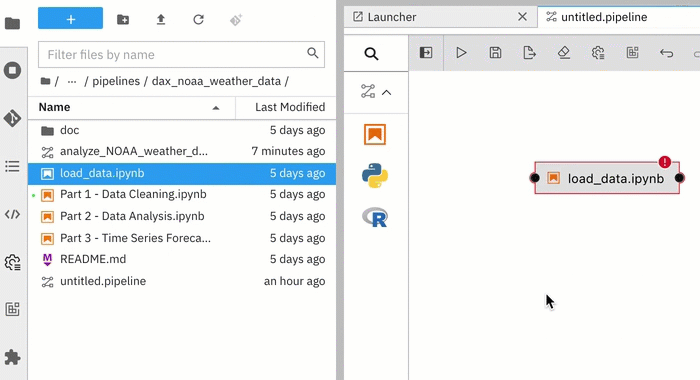
Drag and drop components from the palette onto the canvas or double click on a palette entry.
You can also drag and drop Jupyter notebooks, Python scripts, or R scripts from the JupyterLab File Browser onto the canvas.
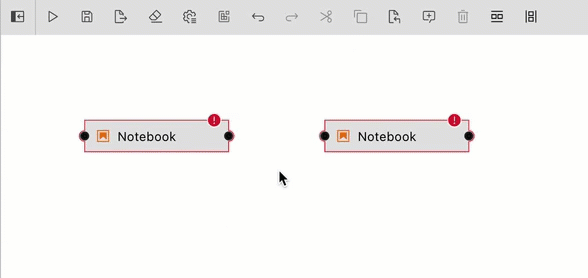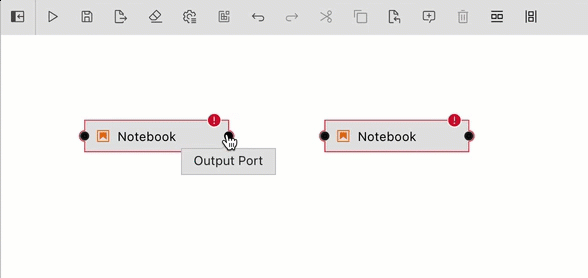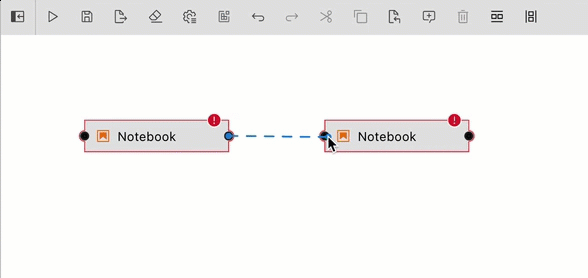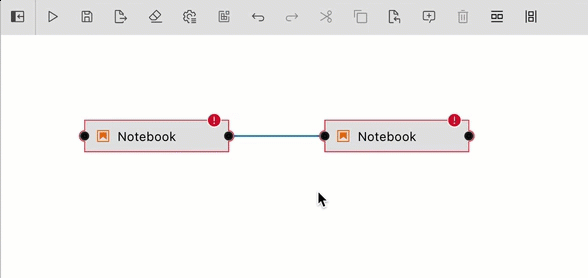
Define the dependencies between nodes by connecting them, essentially creating an execution graph.
Define the runtime properties for each node. Highlight a node, right click, and select
Open Properties. Runtime properties configure a component and govern its execution behavior.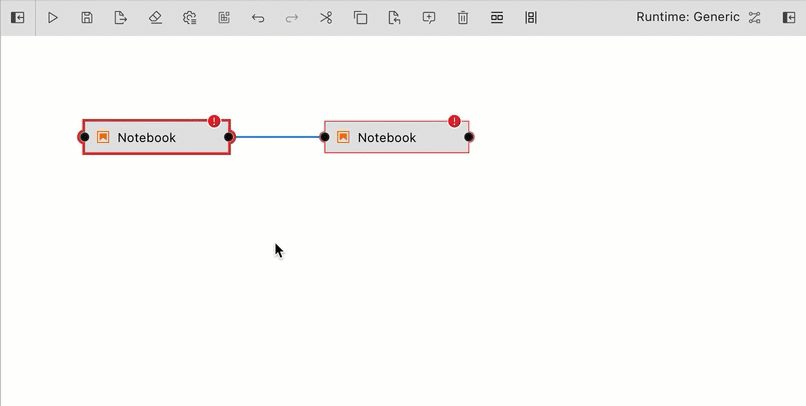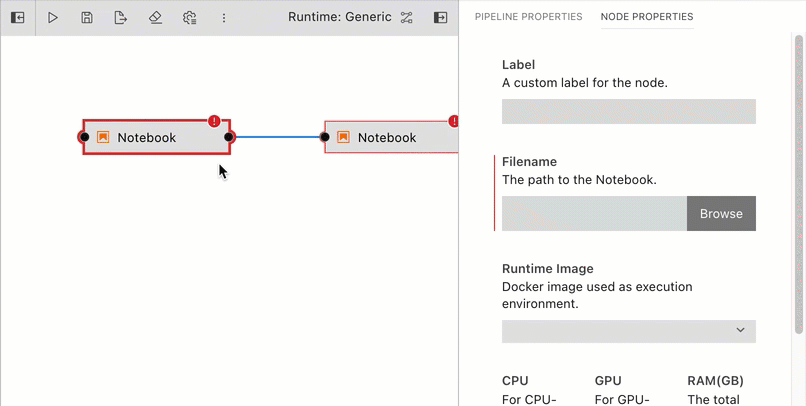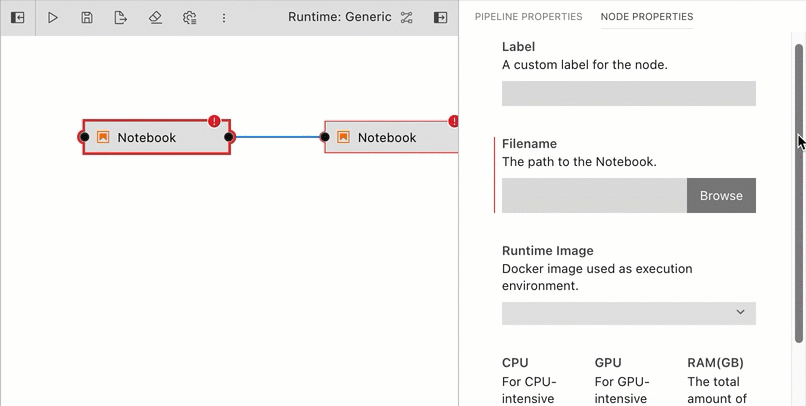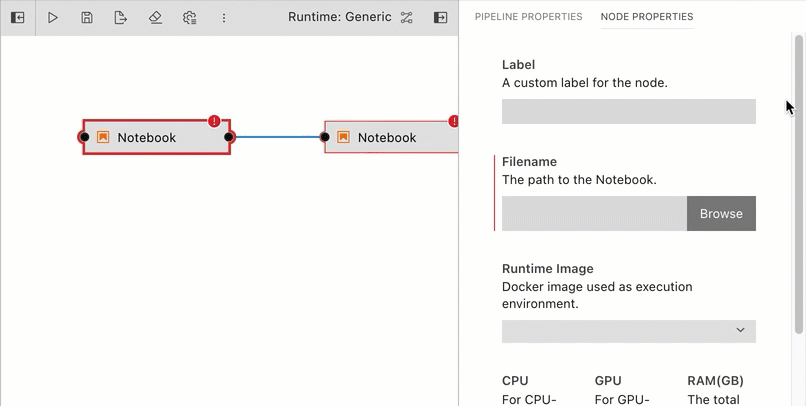
Runtime properties are component specific. For generic components (Jupyter notebook, Python script, and R script) the properties are defined as follows:
Runtime Image
- Required. The container image you want to use to run the notebook or script.
- The value is ignored when the pipeline is executed locally.
- A default runtime image can also be set in the pipeline properties tab. If a default image is set, the Runtime Image property in the node properties tab will indicate that a pipeline default is set. Individual nodes can override the pipeline default value.
- Example:
TensorFlow 2.0
CPU, GPU, and RAM
- Optional. Resources that the notebook or script requires.
- The values are ignored when the pipeline is executed locally.
File Dependencies
- Optional. A list of files to be passed from the local working environment into each respective step of the pipeline. Files should be in the same directory (or subdirectory thereof) as the file it is associated with. Specify one file, directory, or expression per line. Supported patterns are
*and?. - Example:
dependent-script.py
Environment Variables
- Optional. A list of environment variables to be set inside in the container. Specify one variable/value pair per line, separated by
=. - A set of default environment variables can also be set in the pipeline properties tab. If any default environment variables are set, the Environment Variables property in the node properties tab will include these variables and their values with a note that each is a pipeline default. Pipeline default environment variables are not editable from the node properties tab. Individual nodes can override a pipeline default value for a given variable by re-defining the variable/value pair in its own node properties.
- Example:
TOKEN=value
Output Files
- Optional. A list of files generated by the notebook inside the image to be passed as inputs to the next step of the pipeline. Specify one file, directory, or expression per line. Supported patterns are
*and?. - Example:
data/*.csv
Data Volumes
- Optional. A list of Persistent Volume Claims (PVC) to be mounted into the container that executes the Jupyter notebook or script. Format:
/mnt/path=existing-pvc-name. Entries that are empty (/mnt/path=) or malformed are ignored. Entries with a PVC name considered to be an invalid Kubernetes resource name will raise a validation error after pipeline submission or export. The referenced PVCs must exist in the Kubernetes namespace where the node is executed. - Data volumes are not mounted when the pipeline is executed locally.
- Example:
/mnt/vol1=data-pvc
Kubernetes Secrets
- Optional. A list of Kubernetes Secrets to be accessed as environment variables during Jupyter notebook or script execution. Format:
ENV_VAR=secret-name:secret-key. Entries that are empty (ENV_VAR=) or malformed are ignored. Entries with a secret name considered to be an invalid Kubernetes resource name or with an invalid secret key will raise a validation error after pipeline submission or export. The referenced secrets must exist in the Kubernetes namespace where the generic pipeline nodes are executed. - Secrets are ignored when the pipeline is executed locally. For remote execution, if an environment variable was assigned both a static value (via the ‘Environment Variables’ property) and a Kubernetes secret value, the secret’s value is used.
- Example:
ENV_VAR=secret-name:secret-key
Associate each node with a comment to document its purpose.
Save the pipeline file.
Note: You can rename the pipeline file in the JupyterLab File Browser.
Running pipelines¶
Pipelines can be run from the Visual Pipeline Editor and the elyra-pipeline command line interface. Before you can run a pipeline on Kubeflow Pipelines or Apache Airflow you must create a runtime configuration. A runtime configuration contains information about the target environment, such as server URL and credentials.
Running a pipeline from the Visual Pipeline Editor¶
To run a pipeline from the Visual Pipeline Editor:
Click
Run Pipelinein the editor’s tool bar.
For generic pipelines select a runtime platform (local, Kubeflow Pipelines, Apache Airflow) and a runtime configuration for that platform. For runtime-specific pipelines select a runtime configuration.

Elyra does not include a pipeline run monitoring interface for pipelines:
- For local/JupyterLab execution check the console output.
- For Kubeflow Pipelines open the Central Dashboard link.
- For Apache Airflow open the web GUI link.
The pipeline run output artifacts are stored in the following locations:
- For local/JupyterLab execution all artifacts are stored in the local file system.
- For Kubeflow Pipelines and Apache Airflow output artifacts for generic components are stored in the runtime configuration’s designated object storage bucket.
Running a pipeline from the command line interface¶
Use the elyra-pipeline run command to execute a generic pipeline in your JupyterLab environment.
$ elyra-pipeline run elyra-pipelines/a-notebook.pipeline
Use the elyra-pipeline submit command to run a generic or runtime-specific pipeline remotely on Kubeflow Pipelines or Apache Airflow, specifying a compatible runtime configuration as parameter:
$ elyra-pipeline submit elyra-pipelines/a-kubeflow.pipeline \
--runtime-config kfp-shared-tekton
For Kubeflow Pipelines the --monitor option is supported. If specified, the pipeline execution status is monitored for up to --monitor-timeout minutes (default: 60) and the elyra-pipeline submit command terminates as follows:
- pipeline run completes successfully before
--monitor-timeoutis exceeded: exit code 0 - pipeline run does not complete before
--monitor-timeoutis exceeded: exit code 124 (Note: the pipeline continues running on Kubeflow Pipelines, only monitoring is stopped.) - pipeline run on Kubeflow Pipelines fails before
--monitor-timeoutis exceeded: non-zero exit code but not 124
Note: Refer to the Managing runtime configurations using the Elyra CLI topic in the User Guide for details on how to list and manage runtime configurations. If the specified --runtime-config is not compatible with the specified pipeline an error is raised.
Exporting pipelines¶
When you export a pipeline Elyra only prepares it for later execution, but does not upload it to the Kubeflow Pipelines or Apache Airflow server. Export performs two tasks. It packages dependencies for generic components and uploads them to cloud storage, and it generates pipeline code for the target runtime.
Before you can export a pipeline on Kubeflow Pipelines or Apache Airflow you must create a runtime configuration. A runtime configuration contains information about the target environment, such as server URL and credentials.
Exporting a pipeline from the Visual Pipeline Editor¶
To export a pipeline from the Visual Pipeline Editor:
Click
Export Pipelinein the editor’s tool bar.
For generic pipelines select a runtime platform (local, Kubeflow Pipelines, or Apache Airflow) and a runtime configuration for that platform. For runtime-specific pipelines select a runtime configuration.
Select an export format.
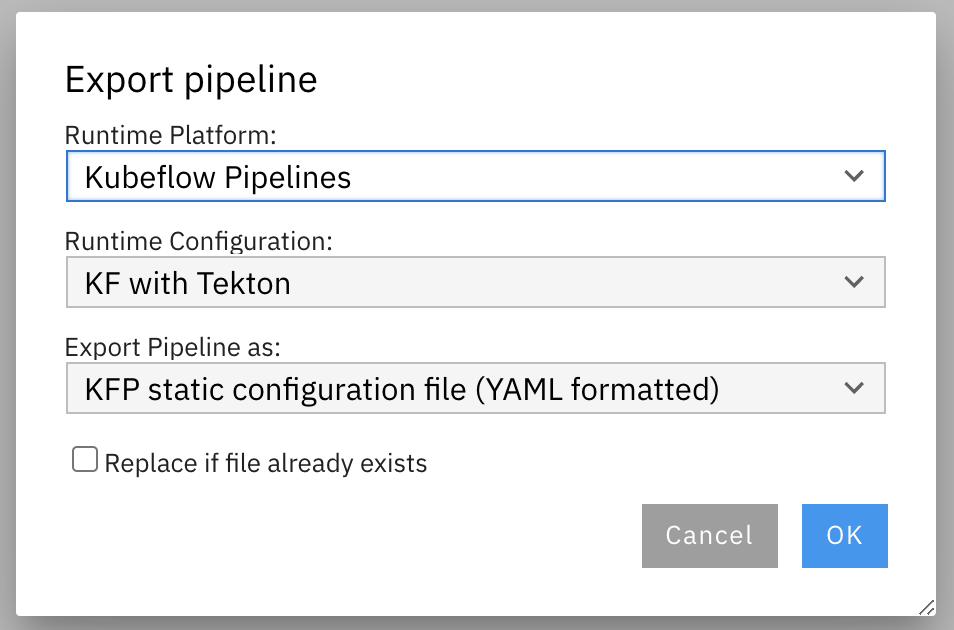
Import the exported pipeline file using the Kubeflow Central Dashboard or add it to the Git repository that Apache Airflow is monitoring.
Exporting a pipeline from the command line interface¶
Use the elyra-pipeline export command to export a pipeline to a runtime-specific format, such as YAML for Kubeflow Pipelines or Python DAG for Apache Airflow.
$ elyra-pipeline export a-notebook.pipeline --runtime-config kfp_dev_env --output /path/to/exported.yaml --overwrite
To learn more about supported parameters, run
$ elyra-pipeline export --help
Note: Refer to the Managing runtime configurations using the Elyra CLI topic in the User Guide for details on how to list and manage runtime configurations. If the specified --runtime-config is not compatible with the specified pipeline an error is raised.
Describing pipelines¶
Describing a pipeline from the command line interface¶
Use the elyra-pipeline describe command to display pipeline information, such as description, version, and dependencies.
$ elyra-pipeline describe a-notebook.pipeline
To learn more about supported parameters, run
$ elyra-pipeline describe --help
The pipeline dependencies output includes:
- Jupyter notebooks
- Python or R scripts
- Local files that the notebooks or scripts require
- Custom components
- Data volumes that generic nodes are mounting
- Container images that generic nodes are using to run notebooks or scripts
- Kubernetes secrets that generic nodes are exposing as environment variables to notebooks or scripts
Specify the --json option to format the output as JSON.